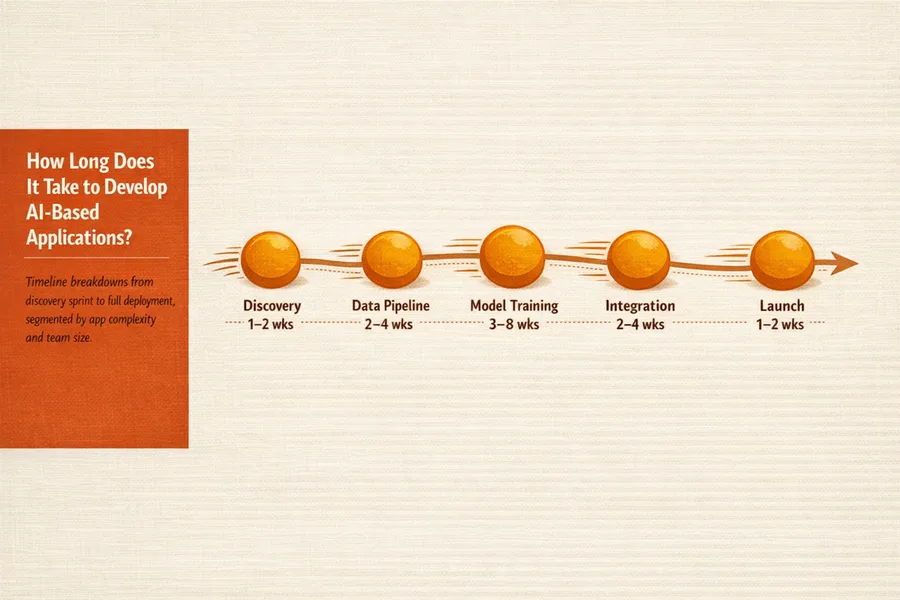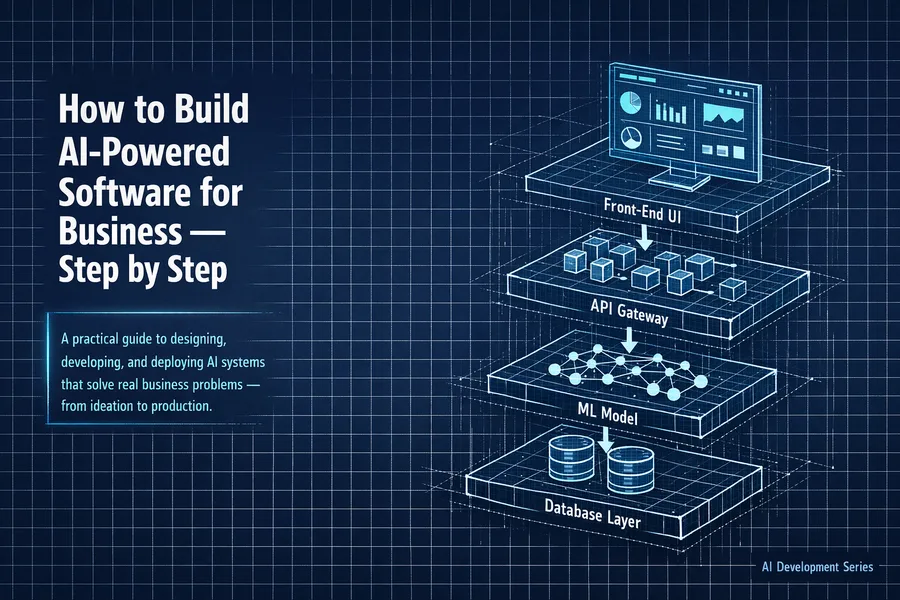
A practical, jargon-light roadmap that walks business owners, product managers, and decision-makers through every phase of bringing an AI software project from idea to production.
Why Most AI Projects Fail Before They Start
Research from leading consulting firms consistently finds that a majority of enterprise AI projects never make it to production — or fail to deliver measurable value when they do. The reason is rarely that the technology does not work. It is almost always that organizations skipped the foundational work: clearly defining the problem, assessing data readiness, and aligning stakeholders on realistic expectations.
The good news is that these failures are preventable. Organizations that approach AI development with a disciplined, stage-gated process succeed at far higher rates than those that rush straight to building a model. What follows is the process that high-performing teams use.
Step 1 — Define a Specific Business Problem
Start with a business outcome, not a technology. Ask: what decision do we make today that takes too long, costs too much, or produces too many errors? The answer to that question is your AI use case.
Strong AI use cases share a few common traits. They involve repetitive decisions made at scale. They have access to historical data that reflects how those decisions played out. And they have a clear, measurable success metric — revenue saved, errors reduced, customer satisfaction improved.
Weak use cases are vague ('use AI to improve operations'), have no available data, or involve one-time decisions that do not benefit from automation. Sorting your ideas into these two buckets early saves enormous time and money.
Step 2 — Audit Your Data
Data is the raw material of AI. Before committing to a development effort, take stock of what you actually have: How much data exists? How far back does it go? Is it labeled — meaning, do you have both the inputs and the correct outputs for historical decisions? Is it stored in a format that can be processed, or is it scattered across spreadsheets, PDFs, and disconnected systems?
This audit frequently reveals that data is messier than anticipated. Duplicate records, inconsistent formatting, missing values, and undocumented schema changes are common. Addressing these issues early — rather than mid-project — is essential.
Step 3 — Assemble the Right Team
A complete AI development team typically includes several distinct skill sets:
- Data engineers who build the pipelines that move and transform raw data
- Data scientists who design and train the machine learning models
- Software engineers who integrate models into production applications
- DevOps or MLOps engineers who manage deployment, monitoring, and infrastructure
- A domain expert — someone who deeply understands the business problem — to guide feature selection and validate outputs
For smaller organizations, these roles are sometimes filled by fewer people wearing multiple hats, or partially outsourced to an AI development partner. What you cannot outsource is the domain expertise: the business context that ensures the model is solving the right problem.
Step 4 — Choose Your Development Approach
Not every AI initiative requires training a model from scratch. Today there are three common pathways:
- Build from scratch: Best when your use case is highly specific, you have proprietary data that provides a competitive advantage, and you have the technical resources to execute. Highest cost, longest timeline, greatest customization.
- Fine-tune a pre-trained model: Foundation models — large AI systems already trained on massive datasets — can be adapted to your specific domain with relatively modest additional training data. This approach has become the dominant path for NLP and generative AI use cases. Faster and cheaper than building from scratch.
- Use AI APIs and platforms: For many common tasks — language translation, image classification, speech transcription, document extraction — commercial AI APIs offer production-ready capabilities that can be integrated with minimal development effort. Fastest time to value, but limited customization and ongoing per-use costs.
Step 5 — Build, Train, and Evaluate
With your approach selected, development begins in earnest. The core loop is: prepare data, train the model, evaluate performance against a held-out test set, identify failures, adjust, and repeat. This loop typically runs many times before the team is confident the model is ready for production.
Key metrics to track during this phase include accuracy (the overall percentage of correct predictions), precision (the percentage of positive predictions that are actually correct), recall (the percentage of actual positives the model identifies), and F1 score (a balanced combination of precision and recall). The appropriate balance between these metrics depends on your use case — a medical diagnosis tool has very different tolerance for false negatives than a product recommendation engine.
Step 6 — Integrate With Your Existing Systems
A model that lives in a data scientist's notebook delivers zero business value. It must be integrated into the workflows, applications, and systems where decisions are actually made. In practice this means packaging the model as an API endpoint, connecting it to your CRM, ERP, or custom application, and building the user interface through which employees or customers will interact with it.
This integration phase is often underestimated. Legacy systems, data format mismatches, latency requirements, and security constraints all introduce real engineering work. Budget accordingly.
Step 7 — Test Rigorously Before Launch
Before go-live, conduct end-to-end testing that covers not just model accuracy but system behavior under realistic conditions. How does the application respond when the model returns a low-confidence prediction? What happens when an upstream data source is unavailable? How does the system behave under peak load? These are engineering questions as much as AI questions.
Also conduct bias and fairness testing — particularly for any application that affects hiring, lending, healthcare, or other high-stakes decisions. Catching problems in testing is far less costly than addressing them after a public incident.
Step 8 — Deploy, Monitor, and Improve
Production deployment is the beginning of the lifecycle, not the end. Monitor model performance continuously. Track the distribution of inputs the model receives in production against the distribution it was trained on — significant divergence is an early warning sign of model drift. Set up automated alerts for performance degradation, and establish a regular retraining cadence.
Treat your AI application like a living system, not a one-time project. Organizations that invest in this ongoing care consistently extract more value from their AI investments than those that treat deployment as a finish line.
Bottom Line: Successful AI software development is 20 percent model building and 80 percent problem definition, data work, integration, and ongoing stewardship. The organizations that understand this ratio are the ones that build AI systems that actually work.