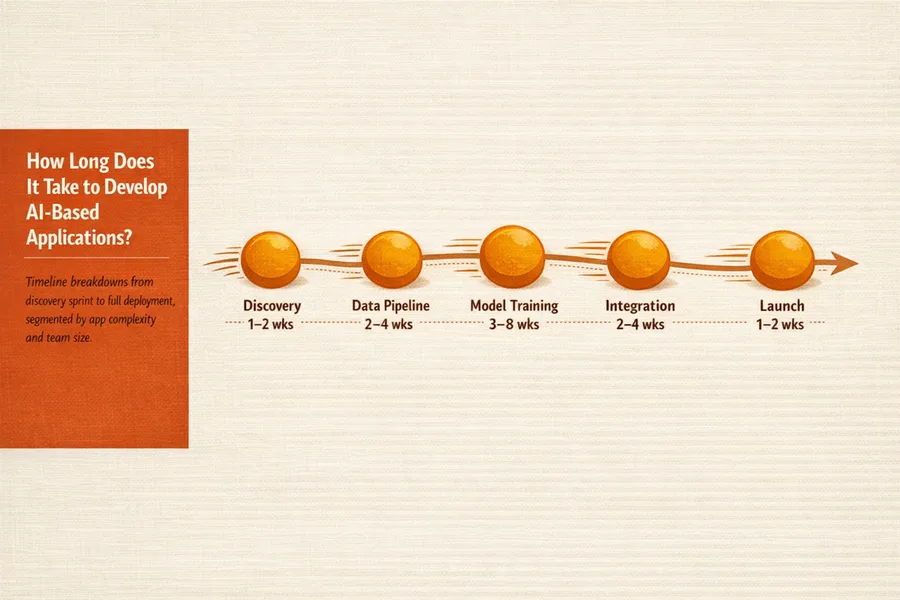
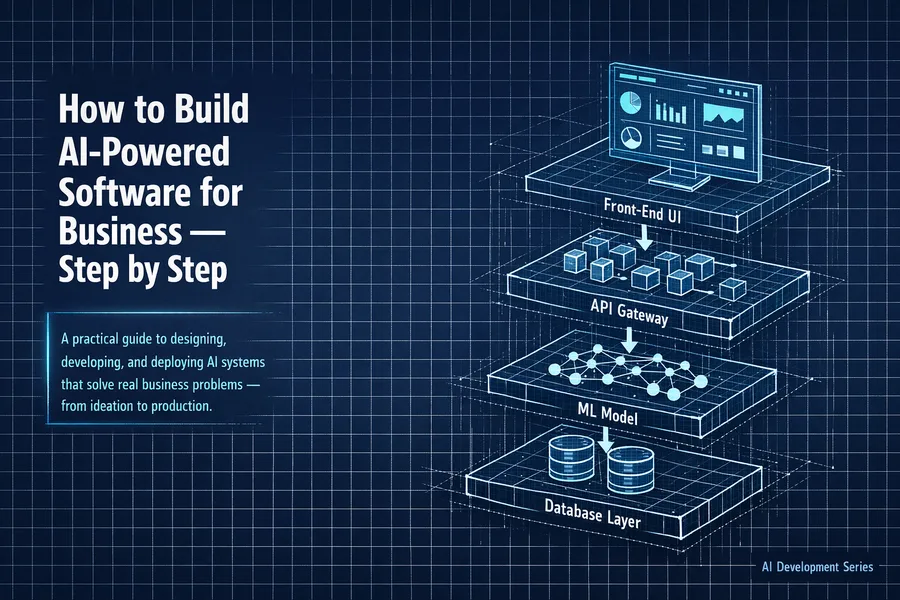
A clear-eyed tour of the programming languages, frameworks, platforms, and infrastructure tools that power modern AI software development — explained for readers who want to understand the landscape without getting lost in acronyms.
The Technology Stack: Layers of the AI Development Ecosystem
AI software development does not run on a single tool or platform. It runs on a layered ecosystem in which different technologies handle different phases of the work — data ingestion, model training, deployment, and monitoring. Understanding how these layers fit together helps you ask better questions of vendors and internal teams, and make more informed investment decisions.
Programming Languages
Python — The Dominant Language
If there is one technology that is truly universal in AI development, it is Python. The language's readable syntax, extensive library ecosystem, and strong community support have made it the default choice for data science and machine learning work across virtually every industry and company size. The overwhelming majority of AI frameworks, academic papers, and tutorials are Python-first. For any team building AI today, Python fluency is a prerequisite.
R
R remains widely used in academic research, pharmaceutical trials, and statistical analysis-heavy applications. It has a rich ecosystem of statistical packages and strong visualization capabilities. In production AI development for business applications, R has largely ceded ground to Python, though many data science teams keep it in the toolbox for specific analytical tasks.
Julia, Scala, and Java
Julia is gaining traction in high-performance scientific computing and quantitative finance. Scala is commonly used with Apache Spark for large-scale distributed data processing. Java and its close relative Kotlin appear in Android AI applications and in enterprise environments where existing Java infrastructure is the norm. These are specialized choices rather than default starting points.
Core Machine Learning and Deep Learning Frameworks
- PyTorch: Developed by Meta's AI Research lab and now the dominant framework for deep learning research and increasingly for production deployment as well. Its dynamic computation graph makes it intuitive for researchers and easier to debug than earlier frameworks. If you are building with neural networks in 2026, there is a very high probability your team is using PyTorch.
- TensorFlow and Keras: Google's TensorFlow and its high-level Keras API remain widely deployed, particularly in production environments where TensorFlow's serving infrastructure and edge deployment capabilities (TensorFlow Lite) are valuable. Many models trained in PyTorch are converted to TensorFlow format for production serving.
- Scikit-learn: The workhorse of classical machine learning. For tabular data and standard ML tasks — classification, regression, clustering, dimensionality reduction — scikit-learn provides clean, well-documented implementations of hundreds of algorithms. Almost every data science team uses it for baseline models and data preprocessing pipelines.
- XGBoost and LightGBM: Gradient boosting frameworks that consistently produce state-of-the-art results on structured tabular data. They are often the first tools a data scientist reaches for when working with the kind of data most businesses actually have — spreadsheets, database exports, transaction records.
- Hugging Face Transformers: The central hub for pre-trained language models and other foundation model architectures. In 2026, Hugging Face is as much an infrastructure layer as a library — its Model Hub hosts tens of thousands of models that developers can download, fine-tune, and deploy. For any NLP work, it is essentially the starting point.
Generative AI and Large Language Model Infrastructure
The rapid growth of generative AI applications has spawned its own infrastructure layer:
- LangChain and LlamaIndex: Frameworks for building applications on top of large language models. They provide abstractions for prompt management, retrieval-augmented generation (connecting models to external knowledge bases), memory management across conversation turns, and chaining multiple AI calls together into complex workflows.
- Vector Databases: AI applications that perform semantic search or retrieval-augmented generation need to store and query high-dimensional vector representations of text, images, or other data. Purpose-built vector databases like Pinecone, Weaviate, Qdrant, and Chroma have become standard components of modern AI stacks.
- Foundation Model APIs: Commercial API access to foundation models — from Anthropic, OpenAI, Google, Meta, Mistral, and others — has dramatically lowered the barrier to building sophisticated AI features. Developers can access world-class language, vision, and reasoning capabilities without training or hosting their own models.
Data Engineering and Pipeline Tools
The infrastructure that moves, transforms, and stores data for AI systems is as important as the models themselves:
- Apache Spark — Distributed data processing for large-scale data transformation and feature engineering
- Apache Kafka — Real-time data streaming, used to feed live data to models that make time-sensitive predictions
- dbt (data build tool) — SQL-based transformation layer popular in modern analytics and ML data preparation
- Airflow and Prefect — Workflow orchestration tools that schedule and manage the pipelines feeding AI systems
- Snowflake, Databricks, BigQuery — Cloud data warehousing and analytics platforms that serve as the foundation for data-driven organizations
MLOps and Model Management Platforms
MLOps — the practice of managing machine learning models in production with the same rigor applied to software systems — has become an entire discipline with its own toolset:
- MLflow: Open-source platform for tracking experiments, packaging models, and managing the model lifecycle. Widely used in teams of all sizes.
- Weights and Biases (W&B): Experiment tracking and visualization platform popular in research-oriented teams and deep learning projects.
- Kubeflow: Kubernetes-native ML pipeline platform for teams that need to scale training and serving workloads on their own infrastructure.
- SageMaker, Vertex AI, Azure ML: Managed ML platforms from AWS, Google, and Microsoft that provide end-to-end tooling — data labeling, training, deployment, monitoring — within each cloud provider's ecosystem. Organizations already committed to a cloud provider typically use the corresponding managed ML platform.
Cloud Infrastructure
The three major U.S. cloud providers — Amazon Web Services, Google Cloud Platform, and Microsoft Azure — all offer comprehensive AI development infrastructure including managed training environments, GPU and TPU compute, model serving endpoints, and specialized AI services for common tasks. Most production AI systems in the United States run on one of these three platforms, or increasingly on multi-cloud architectures.
Edge deployment — running AI models directly on devices rather than in the cloud — is a growing area for latency-sensitive and privacy-sensitive applications. Tools like ONNX Runtime, TensorFlow Lite, and Apple's Core ML support on-device inference across a range of hardware.
Explainability and Responsible AI Tools
As AI systems take on higher-stakes decisions in business contexts, the ability to explain why a model made a particular prediction has moved from a nice-to-have to a regulatory and business requirement:
- SHAP (SHapley Additive exPlanations) — Provides feature importance scores that explain individual model predictions
- LIME — Another model-agnostic explanation method, particularly useful for explaining complex models to non-technical stakeholders
- Fairlearn and AI Fairness 360 — Libraries for assessing and mitigating bias in ML models
- Evidently AI and Fiddler AI — Monitoring platforms that track model performance, data drift, and fairness metrics in production
Looking Ahead: The AI technology landscape evolves faster than virtually any other area of software. The specific tools in use today will continue to shift, but the underlying disciplines — rigorous data engineering, principled model development, robust deployment practices, and ongoing monitoring — will remain the foundations of effective AI software development regardless of which frameworks are fashionable in any given year.