Production AIthat earnsits place.
We help operators ship AI features that move the metric. RAG over your data, agents that automate real work, custom models trained on your domain. Eval-driven, cost-aware, built to run in production.
Five manual steps, or one AI agent.
The same support ticket. A person clicking through five tools for eight minutes, replaced by one agent that finishes the job in seconds.
Six AI capabilities. Tap one to inspect it.
We pick the smallest, most reliable AI architecture that solves the problem in front of us, then we measure it before shipping it.
Embed Claude, GPT, and Gemini into your product with prompt engineering, caching, and cost controls.
From your question to a cited answer, in six hops.
Watch a query flow through the pipeline. This is what runs every time someone asks your assistant a question.
We do not ship AI without numbers next to it.
Six steps designed to ship AI that survives production.
Most AI projects die between demo and production. Every step in our process has a deliverable you can see, test, and approve.
Map the opportunity
Workshop with your team to rank highest-leverage AI use cases by ROI, feasibility, and risk.
Inventory your data
Audit data quality, access, and compliance. Surface gaps before they become roadblocks.
Working demo in weeks
Ship a functional prototype in 2 to 4 weeks. Real models, real data, runnable end-to-end.
Measure honestly
Eval harness with golden datasets, accuracy and latency benchmarks, adversarial test cases.
Ship to production
Hardened deployment with rate limits, fallbacks, observability, and budget guardrails.
Improve continuously
Monitor real usage, A/B test prompts and models, roll improvements forward without breaks.
Use cases we have shipped, across industries.
Support deflection
RAG over knowledge base + ticket history. Resolves common cases, escalates only what needs a human.
Lead enrichment
Agents that research accounts, draft personalized outreach, surface buying signals across CRM and public data.
Document automation
Parse PDFs, contracts, and forms with vision + LLM pipelines. Validate, extract, and route with audit trails.
Risk & fraud signals
Custom classifiers and anomaly detection over transaction streams, tuned to your risk policy.
Clinical document AI
HIPAA-aware extraction from EHRs, intake forms, and clinical notes. PHI handling and on-prem options.
Natural-language ops
A chat layer over your internal data and tools so non-technical teams can query and act without dashboards.
Four things that decide whether AI projects ship, or quietly die.
“Eval-driven, not vibes-driven.”
Every AI feature ships with an eval harness, golden test set, and accuracy thresholds before it goes live. If the number does not move, the feature does not ship.
“Cost-aware by default.”
Token spend instrumented. Prompts cached aggressively. Requests routed to the cheapest model that hits your accuracy bar. Bills that scale with usage, not surprise.
“Hardened for production from day one.”
Rate limits, fallback chains, prompt-injection mitigations, structured outputs, observability built in. Demos that survive contact with real users.
“Senior team, no handoffs.”
The engineers who scope your project also build it. Direct access to senior AI engineers. No offshore handoffs, no junior teams quietly inheriting the work.
Questions, Answered
Frequently Asked Questions
Most AI development projects for small businesses run between $15,000 and $80,000. A focused pilot with one workflow lands on the lower end. Multi-system rollouts with RAG, fine-tuning, and integrations run higher. Every project starts with a $4,000 to $8,000 audit that returns a fixed-price plan.
Practical wins include answering 70 to 90 percent of support tickets without a human, reviewing contracts and extracting key terms, qualifying inbound leads, summarizing long meetings, and searching internal documents in plain English. We focus on tasks that already cost hours of staff time each week.
Yes. We work in your cloud, on your accounts, with read-only or sandboxed access where possible. Sensitive fields are redacted before any data reaches a model. We also document data flow and retention so you can answer questions from clients, auditors, or legal.
All three, picked per project. We use Claude or GPT for most assistants and document tasks, open-source models like Llama or Mistral when cost or privacy demands self-hosting, and smaller fine-tuned models when latency matters. The choice is based on accuracy, cost, and your constraints.
Most pilots are live in four to eight weeks. We measure accuracy, hallucination rate, and cost per task before calling anything production. From there, scaling to more workflows usually takes two to four weeks per workflow.
From Our Blog
Related Insights


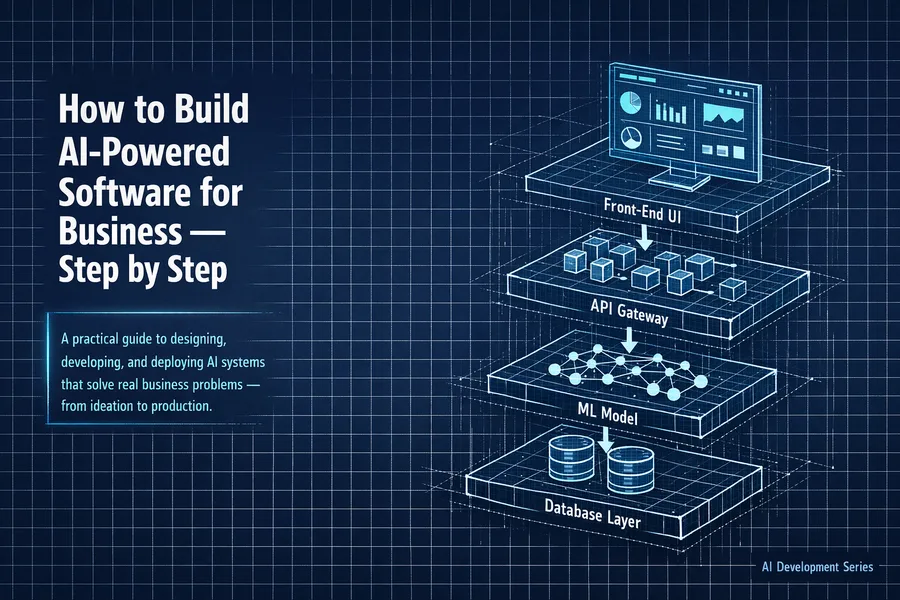
Building at company scale? Explore our enterprise software development services
Have an AI projectin mind?
Tell us the problem in two paragraphs. In a 30-minute call we will tell you whether AI is the right answer, what it would cost, and how we would scope it.